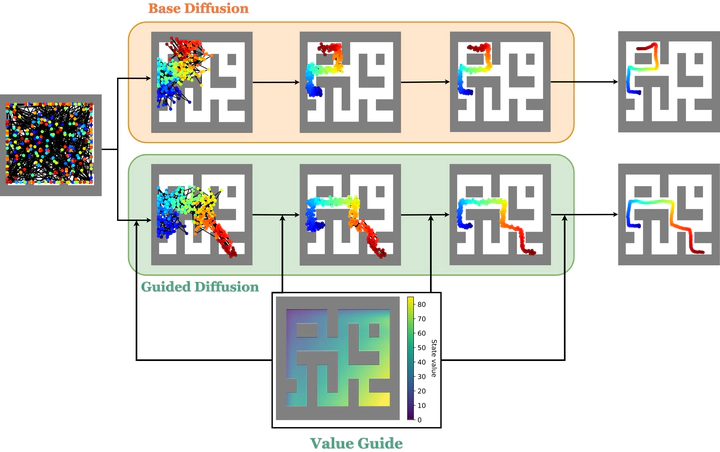
 Guided trajectory-level diffusion schematic.
Guided trajectory-level diffusion schematic.Reinforcement Learning has been applied to great success to tasks where a reward signal reward is clearly defined or can be hand-crafted. However, its application to tasks such as alignment to ethical standards has been limited by the inability to craft a reward function that can balance multiple (and often subjective) preferences. A possible solution is Inverse Reinforcement Learning (IRL), a class of problems in which one learns a reward function from observed agent behaviour.
In this work we propose a method for learning a reward function using diffusion models. Recent work has proposed using diffusion models to learn high-reward policies in sequential decision-making tasks. The general method involves training a diffusion model on a dataset of trajectories in order to learn a model of the environment dynamics, and then using the classifier guidance property of diffusion models to steer their output towards high-return policies. In this work we hypothesise that for a choice of trajectory similarity metric, and given a diffusion model trained on arbitrary trajectories in an environment, and example trajectories of a behaviour we wish to imitate, one can learn a proxy reward function of the desired behaviour (IRL). This learnt reward function can be used to steer the diffusion process towards the behaviour distribution, making our method learn a reward function while also imitating behaviour.
We study the performance of our method across three different environments, evaluating both the quality of the reward function learnt, as well as the quality of the output behaviour. We show our method learns a reward function that induces optimal behaviour in simple environments, outperforming state of the art IRL methods. We extend this method to more complex environments, showing that its performance lags behind in such settings. Finally, we present reasons for the failure modes of our method, and propose possible fixes.