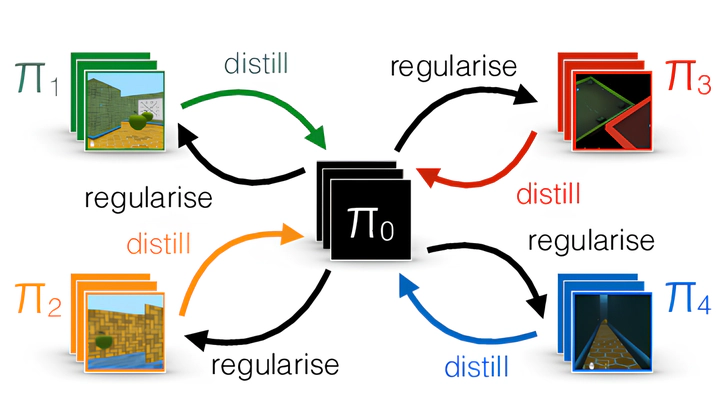
 Graphical description of the Distral framework.
Graphical description of the Distral framework.Multi-task learning has been extensively applied to reinforcement learning problems to counteract its data inefficiency. One possible approach is based on transferring knowledge via policies: Due to the similarity between tasks, an agent’s policy for one task is likely to share similarities with its policy for other tasks. This idea has been applied to single-agent RL to create the Distral Framework: An agent aims to learn a policy for each task, while constrained to find a policy that is similar to a shared policy.
Based on this idea, we propose MultiDistral, an extension of Distral to the multi-agent setting. We show that MultiDistral outperforms a Q-Learning baseline given few games played. However, we observe that learning with MultiDistral in a semi-collaborative setting results in one player’s performance worsening as more iterations are run. We hypothesise from behaviour simulations that this is due to competitiveness, as the better player learns to dominate the competitive resource, resulting in the disadvantaged player having to spend many time steps without the ability to access it and thus learn. We finish by studying the differences between two versions of this framework, as well as by analysing the impact of the different tasks’ characteristics on the learning process.